01
Curated Olympiad problems
Records are drawn from major Olympiad-style competitions and grouped into five combinatorics categories.
A benchmark for rigorous proof reasoning and constructive realization in Olympiad-level combinatorics.
ComBench evaluates large language models on 100 human-annotated competition-level combinatorics problems. It separates proof quality from explicit witness construction through rubric-guided judging and deterministic verifier-gated scoring.
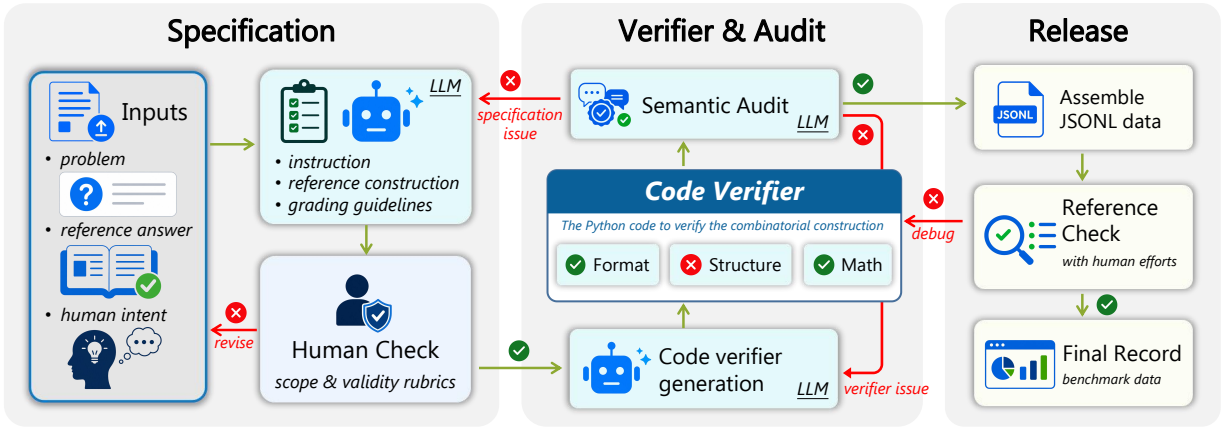
ComBench annotation and verification pipeline.
ComBench is designed to expose whether a model can both prove a combinatorial claim and realize the requested object as a complete, checkable witness.

Distribution of ComBench categories across 100 problems.
Records are drawn from major Olympiad-style competitions and grouped into five combinatorics categories.
Each item has problem-specific 0/1/6/7 grading guidelines for proof-side evaluation.
Construction-centric records require a witness payload checked by deterministic Python verifiers.
The benchmark separates annotation, verification, and scoring so that proof reasoning and construction realization can be analyzed independently.
Human-expert intent, reference answers, and reference witnesses are converted into construction instructions and item-specific grading guidelines.
Each construction task receives deterministic verifier code and a semantic audit for target fidelity and constraint coverage.
Proof scores remain separate from construction validity, then high proof scores are calibrated when the required witness fails verification.
Annotation pipeline diagram | Verifier-gated scoring diagram
ComBench reports average performance and Best@4 under rubric-guided and verifier-gated evaluation.
| Model | Analysis Avg. | Analysis Best@4 | Construction Avg. | Construction Best@4 | Overall Avg. | Overall Best@4 |
|---|---|---|---|---|---|---|
| 1GPT-5.5 | 62.4 | 72.9 | 68.4 | 77.7 | 65.4 | 75.3 |
| 2Gemini-3.1-Pro | 56.1 | 69.7 | 64.5 | 78.3 | 60.3 | 74.0 |
| 3Kimi-K2.6 | 43.5 | 60.6 | 63.4 | 83.7 | 53.5 | 72.1 |
| 4DeepSeek-V4-Pro | 37.8 | 56.6 | 52.6 | 67.7 | 45.2 | 62.1 |
| 5Qwen3.6-Max | 21.4 | 32.9 | 28.4 | 39.1 | 24.9 | 36.0 |
| 6SU-01 | 20.9 | 30.3 | 28.8 | 41.1 | 24.8 | 35.7 |
| 7GLM-5.1 | 21.6 | 36.0 | 25.6 | 37.1 | 23.6 | 36.6 |
| 8Qwen3.6-35B | 17.9 | 26.6 | 22.7 | 32.0 | 20.3 | 29.3 |
| 9Nemotron-Cascade | 21.8 | 32.9 | 17.4 | 28.0 | 19.6 | 30.4 |
| 10Gemma-4-31B-IT | 16.1 | 24.3 | 17.5 | 30.9 | 16.8 | 27.6 |

Proof-error taxonomy used to categorize below-full-credit proof samples.
Kimi-K2.6 trails GPT-5.5 on analysis-centric proof grading but achieves the strongest construction-centric Best@4, showing that constructive realization is not merely a by-product of stronger proof reasoning.
The dominant proof failure is Missing Core Mechanism at 41.2%, followed by Wrong Mathematical Target at 20.0%.
The public code release, arXiv preprint, and dataset are available now. Full result artifacts are maintained separately.
Preprint metadata and PDF are available on arXiv.
arXivEvaluation pipeline, verifier runtime, data-building utilities, tests, and toy examples.
GitHubThe complete ComBench dataset is available on Hugging Face.
Dataset HFDiscuss and upvote ComBench on Hugging Face Daily Papers.
Daily Paper@misc{combench2026,
title = {ComBench: A Benchmark for Rigorous Proof Reasoning and Constructive Realization in Olympiad-Level Combinatorics},
author = {Zhang, Shunkai and Zhang, Haoran and Luo, Yun and Cheng, Qianjia and Lei, Haodi and Li, Yizhuo and Zhan, Runzhe and Wang, Zhilin and Xu, Bangjie and Su, Yucheng and Han, Xinmiao and Qu, Xiaoye and Liu, Dongrui and Lin, Zhouchen and Qiao, Yu and Ding, Ning and Li, Yafu and Cheng, Yu},
year = {2026},
eprint = {2606.10479},
archivePrefix = {arXiv},
primaryClass = {cs.AI},
url = {https://arxiv.org/abs/2606.10479}
}