
SU-01 Pipeline
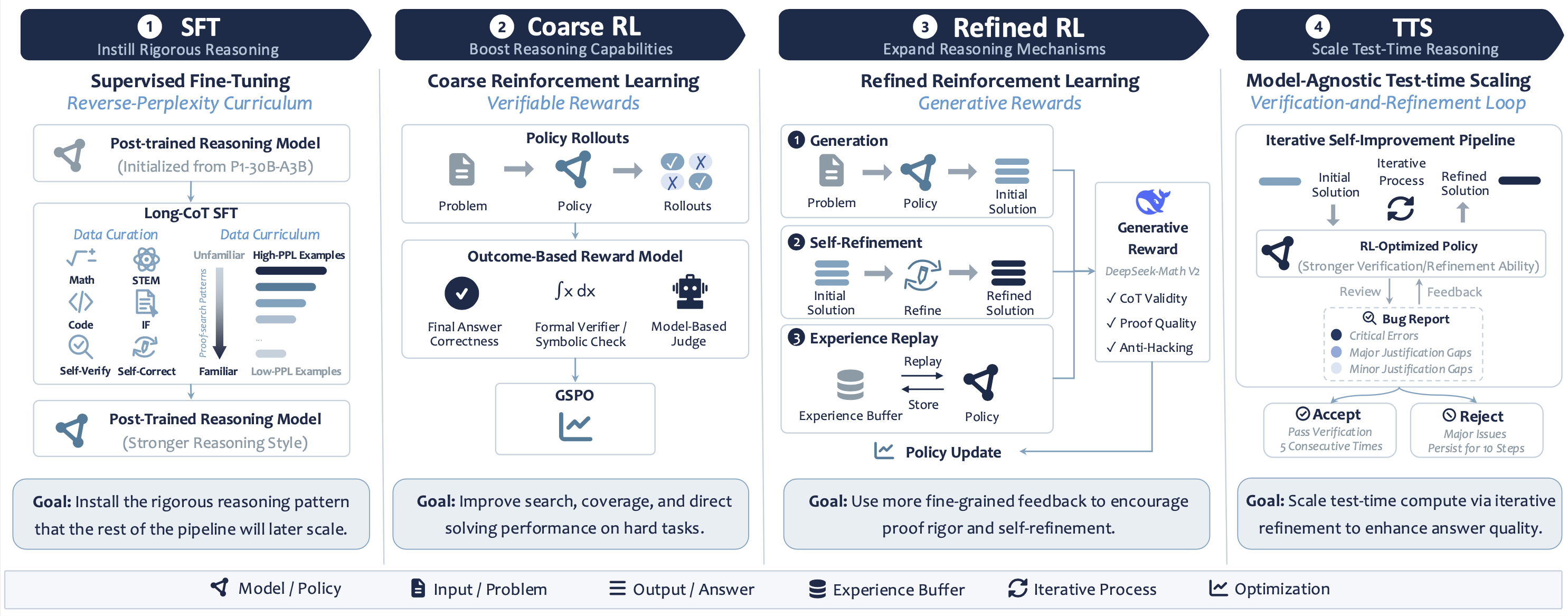
Instilling Rigorous Reasoning via Supervised Fine-tuning
Boosting Reasoning Capability with Reinforcement Learning
Achieving Gold-Medal-Level Reasoning via Test-time Scaling
Results
Core Benchmark Results
Performance on Answer-Verifiable Reasoning Tasks
| Model | AnswerBench | AMO-Bench | AIME 25/26 | FrontierScience-Olympiad | Avg. | |||
|---|---|---|---|---|---|---|---|---|
| Physics | Chemistry | Biology | Overall | |||||
| P1-30B-A3B | 69.3% | 41.3% | 90.4% / 89.6% | 57.5% | 57.5% | 27.5% | 54.5% | 69.0% |
| GLM-4.7-Flash | 73.8% | 53.8% | 91.3% / 88.3% | 54.5% | 60.0% | 17.5% | 53.0% | 72.0% |
| Nemotron-Cascade-2 | 80.5% | 40.8% | 94.2% / 90.0% | 56.0% | 56.3% | 30.0% | 53.5% | 71.8% |
| Qwen3.6-35B-A3B | 78.0% | 58.8% | 92.5% / 92.9% | 65.5% | 74.4% | 25.0% | 65.0% | 77.4% |
| Gemma-4-31B | 74.0% | 39.3% | 88.8% / 91.3% | 69.0% | 61.9% | 27.5% | 61.0% | 70.9% |
| SU-01 | 77.5% | 59.8% | 94.6% / 93.3% | 62.5% | 69.4% | 25.0% | 61.5% | 77.3% |
- The simpler unified post-training recipe realize comparable performance to superior models.
Performance on Non-Verifiable Benchmarks
| Model | IMO-ProofBench | FrontierScience-Research | |||||
|---|---|---|---|---|---|---|---|
| Basic | Advanced | Overall | Physics | Chemistry | Biology | Overall | |
| Larger models | |||||||
| Gemini 3.1 Pro Thinking | 95.2% | 50.0% | 72.6% | 0.0% | 30.0% | 10.0% | 13.3% |
| GPT-5.5-High | 96.7% | 64.8% | 80.7% | 25.0% | 40.0% | 45.0% | 36.7% |
| DeepSeek-V3.2-Speciale | 62.9% | 28.6% | 45.7% | 10.0% | 20.0% | 15.0% | 15.0% |
| Similar-size models | |||||||
| P1-30B-A3B | 33.8% | 6.2% | 20.0% | 0.0% | 10.0% | 0.0% | 3.3% |
| GLM-4.7-Flash | 51.0% | 16.7% | 33.8% | 0.0% | 0.0% | 0.0% | 0.0% |
| Nemotron-Cascade-2 | 77.1% | 28.6% | 52.9% | 5.0% | 5.0% | 20.0% | 10.0% |
| Qwen3.6-35B-A3B | 39.1% | 7.1% | 23.1% | 0.0% | 5.0% | 10.0% | 5.0% |
| Gemma-4-31B | 46.7% | 16.2% | 31.4% | 0.0% | 10.0% | 5.0% | 5.0% |
| SU-01 | 77.1%/91.0% | 38.1%/49.5% | 57.6%/70.2% | 10.0% | 10.0% | 15.0% | 11.7% |
- Strongest result among similar-size models on non-verifiable benchmarks.
- Strong generalization capacity to scientific research-level reasoning.
Performance on Olympiad Competition Problems
| Model | IPhO 2024 | IPhO 2025 |
|---|---|---|
| Similar-size models | ||
| P1-30B-A3B | 23.1 | 17.7 |
| GLM-4.7-Flash | 22.2 | 19.5 |
| Nemotron-Cascade-2 | 21.2 | 16.7 |
| Qwen3.6-35B-A3B | 24.3 | 19.9 |
| Gemma-4-31B | 24.4 | 20.3 |
| SU-01 | 23.5/25.3 | 20.3/21.7 |
| Model | P1 | P2 | P3 | P4 | P5 | P6 | Total |
|---|---|---|---|---|---|---|---|
| SU-01 | 1 | 7 | 1 | 6 | 6 | 0 | 21 |
| SU-01 w/ TTS | 7* | 7* | 7* | 7* | 7* | 0* | 35* |
| Model | P1 | P2 | P3 | P4 | P5 | P6 | Total |
|---|---|---|---|---|---|---|---|
| SU-01 | 7 | 0 | 0 | 7 | 0 | 1 | 15 |
| SU-01 w/ TTS | 7* | 0* | 7* | 7* | 7* | 7* | 35* |
- SU-01 achieves IPhO 2024/2025 gold lines.
- SU-01 TTS achieves IMO 2025 and USAMO 2026 gold lines.
测试时扩展的工作机制
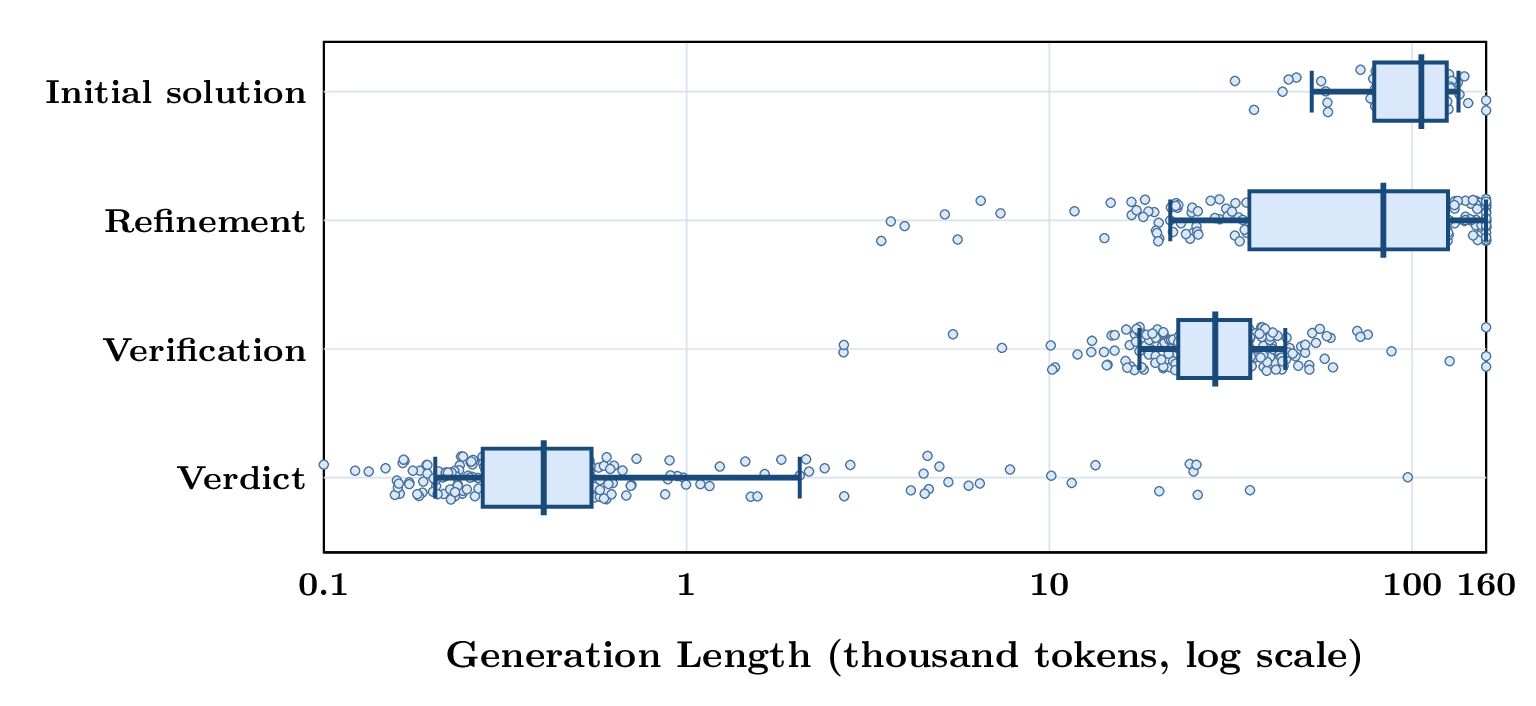
Case Study
IMO 2025
USAMO 2026
Acknowledgements
This work was supported by the Shanghai Artificial Intelligence Laboratory. We thank the authors and maintainers of prior open research and infrastructure that made this work possible. In particular, we are grateful to DeepSeek for open-sourcing strong reasoning policies and generative reward models, which provided an important reference point for our work. IMO-Bench, AMO-Bench, and FrontierScience helped guide the overall system optimization by offering challenging mathematical and scientific reasoning benchmarks and evaluation protocols. We also thank prior data efforts that supported our SFT and RL data curation, including DeepMath, NaturalReasoning, Eurus, OpenCodeReasoning, P1, and OPC, as well as the many public problem sources and communities that cannot all be listed here. We further acknowledge the broader open-source infrastructure ecosystem, including slime for training and SGLang for efficient inference and serving.